定义:redis是一个在内存中存储数据的中间件,用作缓存/支持分布式系统并具备良好的扩展性
数据结构:支持字符串/哈希/列表/集合/有序集合/流
对比mysql,mysql是通过表去进行存储的,是关系型数据库,redis是通过键值对去存储数据的(非关系型存储数据);键值对:key通常是字符串(string),value可以是上述各种结构
主打特点就是快
redis的特性(优点)ipep:
内存数据结构:数据主要存储在内存呢中,可以提供高速访问
可编程性:支持服务端脚本,特别是使用lua语言,除了交互式命令行操作,还可以通过lua脚本批量执行操作
可扩展性:提供api,允许开发者编写自定义扩展,扩展本质是动态链接库
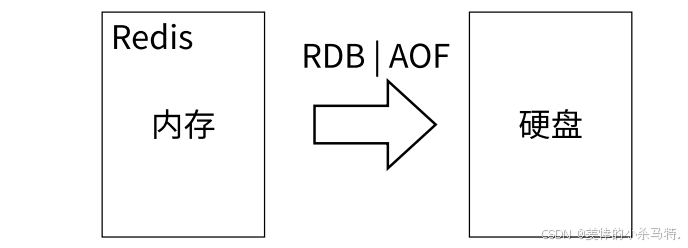
持久化:默认数据存储在内存中,但支持数据持久化到磁盘,目的是避免防止进程退出或者是系统重启导致数据丢失,机制:通过aof(日志)以及rdb(快照)进行持久化
集群:支持分布式集群部署,通过哈希分片将数据分布在多个节点上
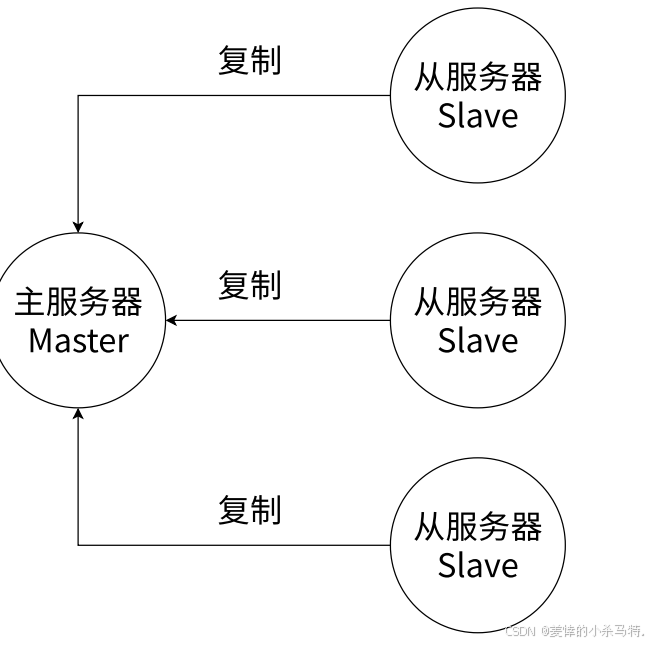
高可用性:支持主从复制,通过配置多个从节点去备份主节点数据
实时数据存储:把redis当作数据库,在大多数情况下,考虑数据持久化情况,优先考虑rdb,因为快
缓存:使用mysql+缓存(redis),采用二八原则,把热点数据存出来,存储在redis中,redis存的都是热数据,全量数据可以以mysql为主的存储,即使redis数据丢失了,也可以从mysql中恢复过来
消息队列:
session存储:
为什么redis快:
数据存储/操作逻辑/io模型/线程模型
1. 基础键值操作
import redis
# 连接Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# 设置键值对
r.set('name', 'Alice') # 设置 name = Alice
r.set('age', 25) # 设置 age = 25
# 获取值
print(r.get('name')) # 输出: b'Alice' (b表示bytes类型)
print(r.get('age')) # 输出: b'25'
# 设置过期时间(秒)
r.setex('temp_session', 30, 'session_data') # 30秒后自动删除
# 检查键是否存在
print(r.exists('name')) # 输出: 1 (存在)
print(r.exists('nonexistent')) # 输出: 0 (不存在)
# 删除键
r.delete('age')
print(r.get('age')) # 输出: None2. 哈希(Hash)类型 – 适合存储对象
# 存储用户信息
r.hset('user:1001', 'name', 'Bob')
r.hset('user:1001', 'email', 'bob@example.com')
r.hset('user:1001', 'age', 30)
# 获取单个字段
print(r.hget('user:1001', 'name')) # 输出: b'Bob'
# 获取所有字段
print(r.hgetall('user:1001'))
# 输出: {b'name': b'Bob', b'email': b'bob@example.com', b'age': b'30'}
# 增加数字字段
r.hincrby('user:1001', 'age', 1) # age增加1
print(r.hget('user:1001', 'age')) # 输出: b'31'3. 列表(List)类型 – 实现队列和栈
# 添加消息到队列
r.lpush('message_queue', 'msg1')
r.lpush('message_queue', 'msg2')
r.lpush('message_queue', 'msg3')
# 获取队列长度
print(r.llen('message_queue')) # 输出: 3
# 从队列右侧取出消息(先进先出)
print(r.rpop('message_queue')) # 输出: b'msg1' (最早的消息)
print(r.rpop('message_queue')) # 输出: b'msg2'
# 作为栈使用(后进先出)
r.lpush('stack', 'item1')
r.lpush('stack', 'item2')
print(r.lpop('stack')) # 输出: b'item2' (最后放入的先出)4. 集合(Set)类型 – 去重和集合运算
# 添加元素到集合
r.sadd('tags', 'python', 'redis', 'database')
r.sadd('tags', 'python') # 重复元素不会被添加
# 获取集合所有成员
print(r.smembers('tags')) # 输出: {b'python', b'redis', b'database'}
# 集合运算
r.sadd('tags2', 'python', 'java', 'javascript')
# 交集
print(r.sinter('tags', 'tags2')) # 输出: {b'python'}
# 并集
print(r.sunion('tags', 'tags2')) # 输出: {b'python', b'redis', b'database', b'java', b'javascript'}5. 有序集合(Sorted Set) – 排行榜实现
# 添加分数和成员
r.zadd('leaderboard', {'Alice': 100, 'Bob': 85, 'Charlie': 120})
# 获取成员排名(从高到低)
print(r.zrevrank('leaderboard', 'Alice')) # 输出: 1 (第二名)
# 获取前3名
print(r.zrevrange('leaderboard', 0, 2, withscores=True))
# 输出: [(b'Charlie', 120.0), (b'Alice', 100.0), (b'Bob', 85.0)]
# 增加分数
r.zincrby('leaderboard', 20, 'Bob') # Bob增加20分
print(r.zscore('leaderboard', 'Bob')) # 输出: 105.06. 发布/订阅模式
import threading
# 订阅者
def subscriber():
pubsub = r.pubsub()
pubsub.subscribe('news')
for message in pubsub.listen():
if message['type'] == 'message':
print(f"收到消息: {message['data'].decode('utf-8')}")
# 启动订阅线程
thread = threading.Thread(target=subscriber)
thread.start()
# 发布者
r.publish('news', '第一条消息')
r.publish('news', '第二条消息')7. 实际应用示例 – 缓存网页内容
import requests
def get_page(url):
# 检查缓存
cache_key = f"page:{url}"
cached_content = r.get(cache_key)
if cached_content:
print("从缓存获取")
return cached_content.decode('utf-8')
# 缓存中没有,从网络获取
print("从网络获取")
response = requests.get(url)
content = response.text
# 缓存1小时
r.setex(cache_key, 3600, content)
return content
# 使用示例
print(get_page('https://example.com'))
print(get_page('https://example.com')) # 第二次会从缓存获取8. 事务操作
# 开始事务
pipe = r.pipeline()
# 添加多个操作
pipe.set('counter', 0)
pipe.incr('counter')
pipe.incrby('counter', 4)
# 执行事务
pipe.execute()
# 获取结果
print(r.get('counter')) # 输出: b'5'9. Lua脚本示例 – 实现原子操作
# 实现原子性的"比较并设置"操作
lua_script = """
local current = redis.call('GET', KEYS[1])
if current == ARGV[1] then
redis.call('SET', KEYS[1], ARGV[2])
return 1
else
return 0
end
"""
# 注册脚本
compare_set = r.register_script(lua_script)
# 使用脚本
r.set('status', 'active')
result = compare_set(keys=['status'], args=['active', 'inactive'])
print(result) # 输出: 1 (修改成功)10. 地理空间(Geo)操作 – 附近位置查询
# 添加地理位置
r.geoadd('stores',
(116.404, 39.915, 'store1'), # 经度, 纬度, 名称
(116.405, 39.916, 'store2'),
(116.406, 39.917, 'store3'))
# 查询附近3公里内的商店
print(r.georadius('stores', 116.404, 39.915, 3, unit='km', withdist=True))
# 输出: [(b'store1', 0.0), (b'store2', 0.1419), (b'store3', 0.2838)]
Redis 基本全局命令详解
Redis 的全局命令是可以对所有数据类型使用的命令,下面我用通俗易懂的方式为你解释这些常用命令:
1. 键(Key)相关命令
KEYS pattern
- 作用:查找所有符合给定模式的 key
- 示例:
KEYS user:*(查找所有以”user:”开头的键) - 注意:生产环境慎用,数据量大时会阻塞服务器
EXISTS key
- 作用:检查 key 是否存在
- 示例:
EXISITS name(检查”name”键是否存在) - 返回:1(存在) 或 0(不存在)
DEL key [key ...]
- 作用:删除一个或多个 key
- 示例:
DEL name age(删除”name”和”age”两个键) - 返回:被删除 key 的数量
TYPE key
- 作用:返回 key 所存储的值的类型
- 示例:
TYPE user:1001 - 可能返回:string, hash, list, set, zset 等
EXPIRE key seconds
- 作用:为 key 设置过期时间(秒)
- 示例:
EXPIRE temp_session 60(60秒后自动删除) - 相关:
TTL key(查看剩余时间),PERSIST key(移除过期时间)
RENAME key newkey
- 作用:重命名 key
- 示例:
RENAME old_name new_name
2. 数据库相关命令
SELECT index
- 作用:切换到指定的数据库(0-15)
- 示例:
SELECT 1(切换到1号数据库)
FLUSHDB
- 作用:清空当前数据库
- 注意:这个命令很危险,会删除当前数据库所有数据
FLUSHALL
- 作用:清空所有数据库
- 注意:极度危险,会删除Redis中所有数据
3. 服务器相关命令
DBSIZE
- 作用:返回当前数据库的 key 数量
- 示例:
DBSIZE(查看当前数据库有多少个key)
INFO [section]
- 作用:获取 Redis 服务器的各种信息和统计数值
- 示例:
INFO memory(查看内存相关信息)
CONFIG GET parameter
- 作用:获取 Redis 配置参数
- 示例:
CONFIG GET maxmemory(查看内存限制配置)
CONFIG SET parameter value
- 作用:修改 Redis 配置(临时生效)
- 示例:
CONFIG SET maxmemory 100mb(设置内存限制)
4. 连接相关命令
PING
- 作用:测试连接是否正常
- 返回:
PONG(表示连接正常)
ECHO message
- 作用:打印给定的字符串
- 示例:
ECHO "Hello Redis"
QUIT
- 作用:关闭当前连接
5. 实用命令
RANDOMKEY
- 作用:随机返回当前数据库的一个 key
- 用途:可用于抽样检查数据
SCAN cursor [MATCH pattern] [COUNT count]
- 作用:增量迭代数据库中的 key (比 KEYS 更安全)
- 示例:
SCAN 0 MATCH user:* COUNT 10
MOVE key db
- 作用:将当前数据库的 key 移动到另一个数据库
- 示例:
MOVE temp_data 1(移动到1号数据库)
通俗解释
可以把 Redis 想象成一个有很多抽屉(数据库)的大柜子,每个抽屉里放着各种盒子(key),盒子里装着不同类型的数据:
- 找东西:
KEYS是打开抽屉大喊”谁的名字以A开头?”,SCAN是慢慢翻找 - 检查盒子:
EXISTS看盒子是否存在,TYPE看盒子里装的是什么类型的东西 - 清理:
DEL是扔掉盒子,EXPIRE是设置定时自动扔掉 - 整理:
RENAME是给盒子贴新标签,MOVE是把盒子放到另一个抽屉 - 大扫除:
FLUSHDB是清空一个抽屉,FLUSHALL是把整个柜子清空
记住这些命令就像记住整理房间的工具,合理使用可以让你的 Redis “房间”保持整洁有序!